WhatsApp-Medien-Nachrichten in Webhooks verarbeiten (Bilder, Dokumente, Sprachnotizen)
22. Mai 2026
·
16 Min. Lesezeit
In diesem Leitfaden: Referenztabelle der Medientypen · Das 5-Minuten-URL-Ablaufen · Vollständige Download-Pipeline · Alle Medien-Payload-Schemas · Bild- und Dokumentenhandling · Sprachnachricht OGG→MP3 Konvertierung · Whisper-Transkription · S3/GCS-Speichermuster · Vollständiger Handler für alle Typen · Normalisiertes SocialHook-Format
Medientypen: vollständige Referenztabelle
Die Cloud API liefert 8 Mediennachrichtentypen, jeweils mit unterschiedlichen Formaten, Größenlimits und Handlinganforderungen. Kennen Sie die Einschränkungen, bevor Sie den Handler erstellen.
type-Wert
Akzeptierte Formate
Größenlimit
Besondere Hinweise
🖼️
image
JPEG, PNG
5 MB
Optionales caption. GIF nicht inline unterstützt — als Dokument senden.
🎵
audio
AAC, AMR, MP3, OGG/Opus
16 MB
voice: true wenn in der App aufgenommen (OGG/Opus). Reguläre Audiodateien können variieren. Immer OGG vor der Transkription konvertieren.
🎬
video
MP4, 3GPP
16 MB
Optionales caption. H.264-Video + AAC-Audio für breiteste Kompatibilität empfohlen.
animated: true wenn animiert. WebP-Format — Browser unterstützen es jetzt nativ.
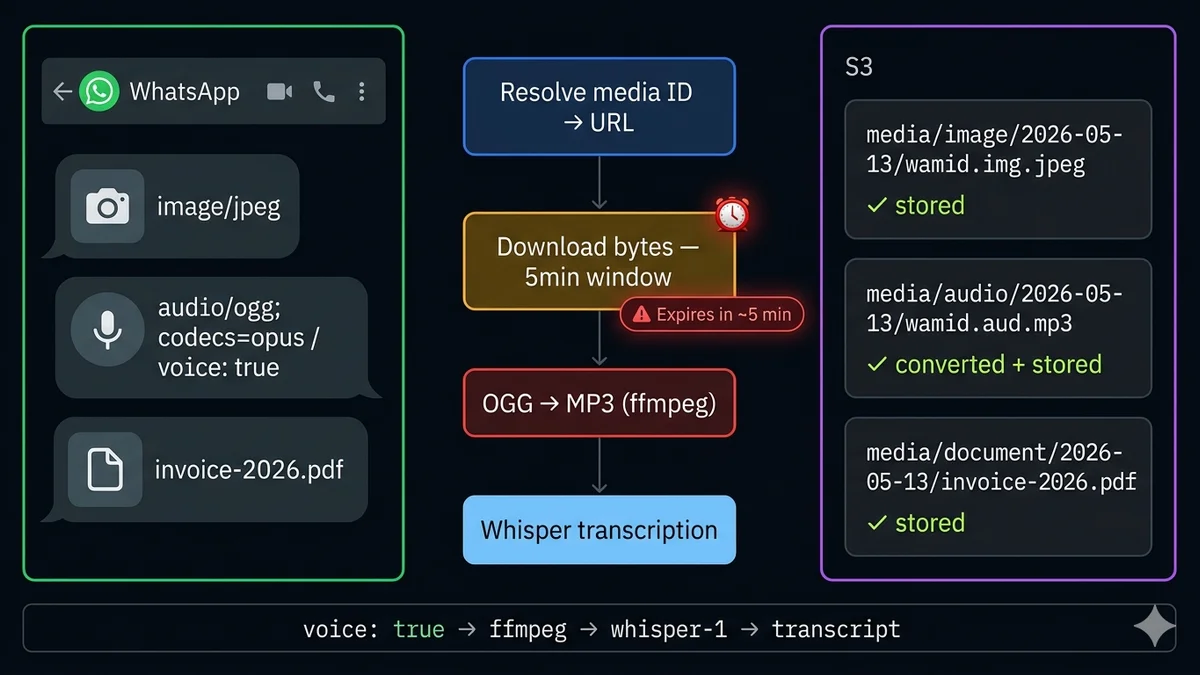
Das 5-Minuten-URL-Ablaufen — das Detail, das die meisten Implementierungen zum Scheitern bringt
Dies ist das am häufigsten übersehene Detail beim WhatsApp-Medienhandling und verursacht die meisten Produktionsfehler. Wenn Sie den Cloud API Media-Endpunkt aufrufen, um eine Medien-ID aufzulösen, erhalten Sie eine temporäre Download-URL. Diese URL ist für ca. 5 Minuten gültig.
Die zwei Muster, die Entwickler verwenden — und warum eines scheitert:
❌ URL speichern, später herunterladen — Sie empfangen den Webhook, rufen den Media-Endpunkt auf, speichern die temporäre URL in Ihrer Datenbank für asynchrone Verarbeitung. Bis Ihr Worker sie aufgreift, ist die URL abgelaufen. Sie erhalten einen 403. Dieses Muster scheitert.
✓ Sofort herunterladen, Datei speichern — Sie empfangen den Webhook, lösen sofort die Medien-ID zu einer URL auf, laden sofort die Bytes herunter, speichern die Datei in Ihrem eigenen Speicher (S3, GCS, Festplatte), speichern nur den Speicherpfad in Ihrer Datenbank. Die asynchrone Verarbeitung arbeitet mit der gespeicherten Datei. Dieses Muster ist korrekt.
Alternative: Medien-ID speichern, bei Bedarf auflösen. Wenn Sie die Datei nicht sofort benötigen, können Sie nur die Medien-ID speichern und sie bei Bedarf frisch auflösen. Medien-IDs sind 30 Tage gültig — viel länger als die temporäre Download-URL. Dies ist nützlich, wenn Sie nicht sicher sind, ob Sie die Binärdatei jemals benötigen werden (z. B. Sticker, die Sie möglicherweise ignorieren). Beachten Sie jedoch, dass der Auflösungsaufruf Latenz hinzufügt, wenn Sie ihn schließlich benötigen.
Die Download-Pipeline: ID → URL → Bytes → Speicher
1
Webhook empfangen — Medien-ID extrahieren
msg.image.id / msg.audio.id / msg.document.id — KEINE URL, nur eine Referenz
2
Sofort HTTP 200 zurückgeben das zuerst
An Meta bestätigen, bevor Downloads beginnen. Medienverarbeitung in asynchrone Warteschlange schieben.
3
Medien-ID → temporäre Download-URL auflösen
GET graph.facebook.com/v21.0/{media_id} — erfordert Authorization: Bearer {token} — gibt url (läuft ~5min ab) + mime_type + file_size zurück
4
Datei-Bytes herunterladen innerhalb von 5 Minuten
GET {download_url} — erfordert AUCH Authorization: Bearer {token} — gibt rohe Binär-Bytes zurück
Bild: Metadaten extrahieren, Miniaturansicht erstellen. Audio/Sprache: OGG→MP3 konvertieren, transkribieren. Dokument: Text für Suche extrahieren. Video: Miniaturansichtsframe erstellen.
Payload-Schemas für jeden Medientyp
Hier ist die genaue Webhook-Value-Objektstruktur für jeden Medientyp. Die Verschachtelung aus der obersten Ebene des Envelopes (entry[0].changes[0].value.messages[0]) ist bereits extrahiert, wenn das normalisierte Format von SocialHook verwendet wird.
Bilder und Dokumente teilen dasselbe zweistufige Download-Muster. Der wesentliche Unterschied: Dokumente enthalten ein filename-Feld, das Sie in Ihrem Speicherschlüssel beibehalten sollten — es ist der Name, den der Kunde der Datei gegeben hat, und was Sie in Ihrer UI anzeigen möchten.
In WhatsApp aufgenommene Sprachnachrichten sind im OGG/Opus-Format kodiert. Sie können sie am voice: true-Flag im Audio-Payload und dem Wert mime_type: "audio/ogg; codecs=opus" erkennen. Dieses Format wird von OpenAI Whisper für die Transkription nicht unterstützt und hat begrenzte Browser-Wiedergabeunterstützung.
Die Lösung: Mit ffmpeg in MP3 konvertieren. ffmpeg ist das universelle Audio-Konvertierungstool, auf jedem wichtigen Betriebssystem und in allen Cloud-Umgebungen verfügbar.
Sprachnachrichten mit OpenAI Whisper transkribieren
Wenn Sie das MP3 haben, senden Sie es an die Whisper-API von OpenAI. Whisper unterstützt 57 Sprachen, verarbeitet Hintergrundgeräusche gut und kostet ca. $0,006 pro Audiominute — eine 30-Sekunden-Sprachnachricht kostet weniger als einen Cent zum Transkribieren. Die Transkription wird dann zu abfragbarem, KI-verarbeitbarem Text.
Was mit der Transkription zu tun ist: Speichern Sie sie neben der Audiodatei. Übergeben Sie sie als Benutzernachricht an Ihren KI-Agenten (anstatt „Audionachricht empfangen"). Indizieren Sie sie in Ihrer Suchdatenbank. Protokollieren Sie sie in Ihrem CRM als Konversationstext. Kunden senden Sprachnachrichten, weil Tippen langsamer ist — das Behandeln ihrer Sprachnachrichten als durchsuchbaren Text verbessert die Fähigkeit Ihres KI-Agenten, korrekt zu verstehen und zu antworten, erheblich.
Speichermuster: Mediendateien organisieren
Wie Sie Dateien in S3 oder GCS organisieren, ist wichtig für Leistung, Abrechnung und Debugging. Hier ist das Speicherschlüsselmuster, das sauber über mehrere Clients und Nachrichtentypen skaliert:
Eine Funktion, die ein normalisiertes Medienereignis empfängt und je nach Typ zum richtigen Handler weiterleitet:
Node.js — universal media dispatcher
mediaDispatcher.js
async functiondispatchMedia(event) {
const { from, message } = event;
const { type } = message;
// Text messages — not media, handle separatelyif (type === 'text') returnhandleText(from, message.text.body);
// Non-media message typesif (['location', 'contacts', 'reaction', 'interactive'].includes(type)) {
returnhandleNonMedia(from, message);
}
// Media types — all require downloadswitch (type) {
case'image':
case'video':
case'sticker':
case'document': {
const result = awaithandleMediaMessage(message, from);
awaitsaveMediaRecord(from, result);
break;
}
case'audio': {
// Voice notes get transcribed; regular audio files just storedconst result = awaitprocessVoiceNote(message, from);
awaitsaveMediaRecord(from, result);
// If voice note was transcribed, treat transcript as text inputif (result.transcript?.text) {
console.log(`Voice note from ${from}: "${result.transcript.text}"`);
awaithandleText(from, result.transcript.text, { isVoiceNote: true });
}
break;
}
default:
console.warn(`Unhandled media type: ${type}`);
}
}
SocialHook: vorab extrahierte Medien-IDs im normalisierten Format
Wenn Sie SocialHook verwenden, kommt der Medien-Payload bereits aus dem verschachtelten Cloud API-Envelope von Meta extrahiert an. Anstatt durch entry[0].changes[0].value.messages[0] zu navigieren, erhalten Sie ein flaches Ereignis:
SocialHook normalized media event
// Image message
{
"platform": "whatsapp",
"event": "message.received",
"from": "+1 555 000 1234",
"message": {
"type": "image",
"id": "wamid.HBgL...",
"image": {
"id": "12345678901234", // ← use this to resolve URL"mime_type": "image/jpeg",
"caption": "Here's the damage to my package"
}
},
"signature_verified": true
}
// Voice note
{
"message": {
"type": "audio",
"audio": {
"id": "98765432109876",
"mime_type": "audio/ogg; codecs=opus",
"voice": true// ← this tells you to run OGG→MP3 conversion
}
}
}
Ihre obige dispatchMedia(event)-Funktion empfängt dieses Format direkt — keine zusätzliche Analyse erforderlich. Die Medien-ID befindet sich unter event.message.image.id (oder .audio.id, .document.id usw.), bereit zum Einspeisen in resolveMediaUrl().
FAQ
Häufige Fragen
Wie lade ich Medien von einem WhatsApp Cloud API Webhook herunter?
Zwei Schritte: (1) Rufen Sie GET graph.facebook.com/v21.0/{media_id} mit Ihrem Zugriffstoken auf, um eine temporäre Download-URL zu erhalten. (2) Rufen Sie diese URL ab (ebenfalls mit Ihrem Zugriffstoken im Authorization-Header), um die Datei-Bytes zu erhalten. Sofort herunterladen — die URL läuft in ca. 5 Minuten ab. Speichern Sie die Datei-Bytes auf S3/GCS/Festplatte, nicht die temporäre URL.
Warum gibt meine WhatsApp-Medien-Download-URL 403 zurück?
Zwei Ursachen: (1) URL abgelaufen — WhatsApp-Medien-Download-URLs sind ca. 5 Minuten gültig. Wenn Sie die URL gespeichert und später abgerufen haben, ist sie abgelaufen. Erneut von der Medien-ID auflösen. (2) Fehlender Authorization-Header — die Download-URL selbst erfordert auch Authorization: Bearer {ACCESS_TOKEN} in der Anfrage. WhatsApp-Medien-URLs sind keine öffentlichen CDN-URLs.
In welchem Format sind WhatsApp-Sprachnachrichten und wie konvertiere ich sie?
WhatsApp-Sprachnachrichten sind im OGG/Opus-Format (erkennbar an voice: true im Payload und mime_type: "audio/ogg; codecs=opus"). Mit ffmpeg in MP3 konvertieren: ffmpeg -i input.ogg -codec:a libmp3lame -qscale:a 2 output.mp3. OGG/Opus wird von OpenAI Whisper oder den meisten Browsern nicht unterstützt — immer vor Transkription oder Wiedergabe konvertieren. Vollständiger Node.js- und Python-Code befindet sich im obigen Abschnitt zu Sprachnachrichten.
Wie transkribiere ich WhatsApp-Sprachnachrichten mit Whisper?
OGG herunterladen → mit ffmpeg in MP3 konvertieren → an die OpenAI Audio Transcriptions API senden mit model: "whisper-1". Whisper gibt den Transkriptionstext zurück. Kosten ca. $0,006 pro Audiominute. Eine 30-Sekunden-Sprachnachricht kostet weniger als ein Drittel Cent. Die Transkription kann dann von Ihrem KI-Agenten oder CRM als reguläre Textnachricht behandelt werden.
Wie lange sind WhatsApp-Medien-IDs gültig?
Medien-IDs sind 30 Tage gültig. Die temporäre Download-URL, die Sie durch Auflösen der ID erhalten, ist ca. 5 Minuten gültig. Das bedeutet, Sie können sicher nur die Medien-ID in Ihrer Datenbank speichern und sie bei Bedarf frisch auflösen (innerhalb von 30 Tagen). Nach 30 Tagen werden die Medien von Metas Servern gelöscht und die ID ist ungültig.
Welche Dateigrößenbeschränkungen gelten für WhatsApp-Medien?
Nach Typ: Bild (JPEG, PNG) — 5 MB. Audio — 16 MB. Video — 16 MB. Dokument — 100 MB. Sticker — 500 KB statisch, 100 KB animiert. Nachrichten mit Medien, die diese Limits überschreiten, werden abgelehnt, bevor Ihr Webhook ausgelöst wird — der Absender sieht einen Fehler, nicht Sie.
Ihre Pipeline beginnt mit einem sauberen Webhook-Ereignis.
SocialHook liefert jedes WhatsApp-Medienereignis — Bild, Sprachnachricht, Dokument — als vorab extrahiertes JSON an Ihren Handler. Sie erhalten die bereite Medien-ID zum Auflösen, den MIME-Typ und das Sprach-Flag. Kein Cloud API-Parsing. Direkt in Ihre Download-Funktion einleiten.
Aufhören, Meta APIs zu verwalten. Anfangen zu bauen.
Verbinde dein erstes Facebook-, Instagram- oder WhatsApp-Konto in unter 2 Minuten. Dein Webhook erhält sein erstes Payload, bevor dein Kaffee kalt wird.