Comment gérer les messages multimédias WhatsApp dans les webhooks (images, documents, notes vocales)
22 mai 2026
·
16 min de lecture
Dans ce guide : Tableau de référence des types de médias · L'expiration en 5 minutes de l'URL · Pipeline de téléchargement complet · Tous les schémas de payload médias · Gestion des images et documents · Conversion note vocale OGG→MP3 · Transcription Whisper · Modèles de stockage S3/GCS · Handler complet pour tous les types · Format normalisé SocialHook
Types de médias : tableau de référence complet
La Cloud API fournit 8 types de messages média, chacun avec des formats différents, des limites de taille et des exigences de gestion. Connaissez les contraintes avant de construire le handler.
valeur type
Formats acceptés
Limite de taille
Notes spéciales
🖼️
image
JPEG, PNG
5 Mo
Optionnel caption. GIF non supporté en ligne — envoyer comme document.
🎵
audio
AAC, AMR, MP3, OGG/Opus
16 Mo
voice: true si enregistré dans l'app (OGG/Opus). Les fichiers audio réguliers peuvent varier. Toujours convertir OGG avant transcription.
🎬
video
MP4, 3GPP
16 Mo
Optionnel caption. Vidéo H.264 + audio AAC recommandés pour une meilleure compatibilité.
📄
document
Tout type MIME accepté par Meta
100 Mo
Inclut filename — conservez-le. PDF, DOCX, XLSX, images en tant que documents, etc.
💿
sticker
WebP
Statique 500 Ko / Animé 100 Ko
animated: true si animé. Format WebP — les navigateurs le supportent nativement désormais.
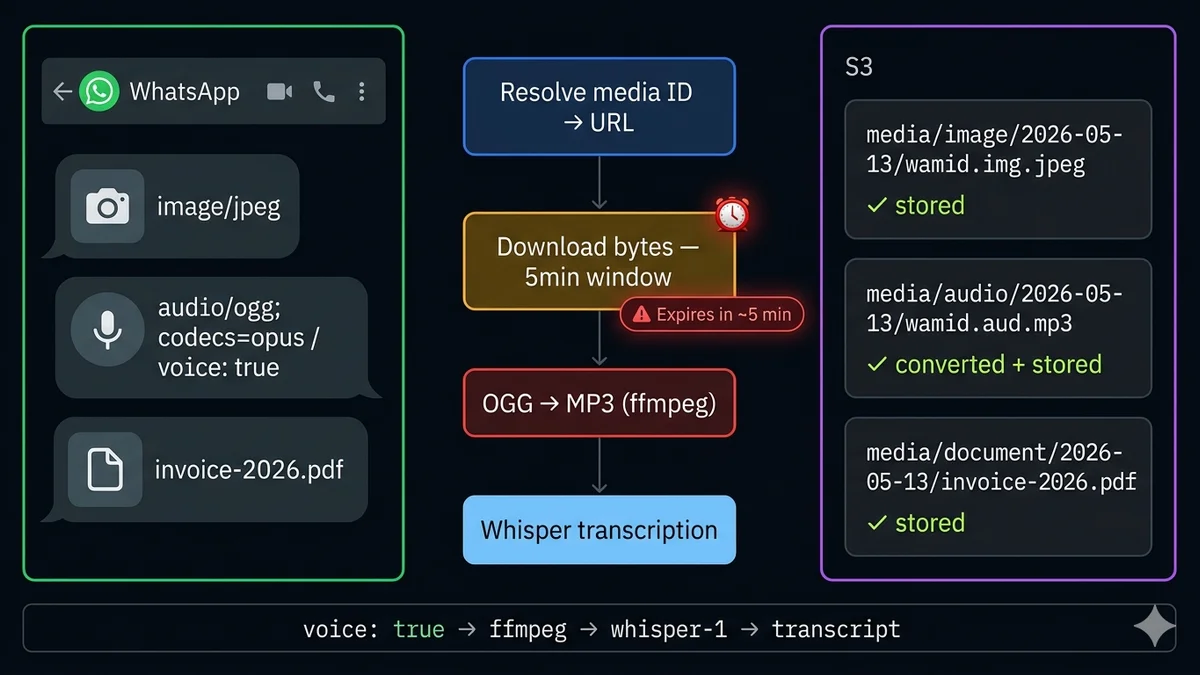
L'expiration en 5 minutes — le détail qui brise la plupart des implémentations
C'est le détail le plus souvent manqué dans la gestion des médias WhatsApp, et il cause la plupart des bugs en production. Lorsque vous appelez l'endpoint média de la Cloud API pour résoudre un ID média, vous recevez une URL de téléchargement temporaire. Cette URL est valide pendant environ 5 minutes.
Les deux patterns utilisés par les développeurs — et pourquoi l'un échoue :
❌ Stocker l'URL, télécharger plus tard — vous recevez le webhook, appelez l'endpoint média, stockez l'URL temporaire dans votre base de données pour un traitement asynchrone. Au moment où votre worker la récupère, l'URL a expiré. Vous obtenez un 403. Ce pattern échoue.
✓ Télécharger immédiatement, stocker le fichier — vous recevez le webhook, résolvez immédiatement l'ID média en URL, téléchargez immédiatement les octets, stockez le fichier sur votre propre stockage (S3, GCS, disque), enregistrez uniquement le chemin de stockage dans votre base de données. Le traitement asynchrone fonctionne sur le fichier stocké. Ce pattern est correct.
Alternative : stocker l'ID média, résoudre à la demande. Si vous n'avez pas besoin du fichier immédiatement, vous pouvez stocker uniquement l'ID média et le résoudre lorsque vous avez besoin du fichier. Les IDs médias sont valides pendant 30 jours — bien plus longtemps que l'URL de téléchargement temporaire. C'est utile quand vous n'êtes pas sûr d'avoir jamais besoin du binaire (ex. stickers que vous pourriez ignorer). Sachez simplement que l'appel de résolution ajoute de la latence quand vous en avez finalement besoin.
Le pipeline de téléchargement : ID → URL → octets → stockage
1
Recevoir webhook — extraire l'ID média
msg.image.id / msg.audio.id / msg.document.id — PAS une URL, juste une référence
2
Retourner HTTP 200 immédiatement faites ceci en premier
Accusez réception à Meta avant tout téléchargement. Poussez le traitement média vers la file asynchrone.
3
Résoudre l'ID média → URL de téléchargement temporaire
Télécharger les octets du fichier dans les 5 minutes
GET {download_url} — nécessite AUSSI Authorization: Bearer {token} — retourne les octets binaires bruts
5
Stocker le fichier sur S3 / GCS / disque local
Organiser par : media/{client_id}/{media_type}/{date}/{media_id}.{ext}
6
Traiter (spécifique au type)
Image : extraire les métadonnées, générer une miniature. Audio/voix : convertir OGG→MP3, transcrire. Document : extraire le texte pour la recherche. Vidéo : générer une frame miniature.
Schémas de payload pour chaque type de média
Voici la structure exacte de l'objet value du webhook pour chaque type de média. L'imbrication depuis l'enveloppe de niveau supérieur (entry[0].changes[0].value.messages[0]) est déjà extraite lors de l'utilisation du format normalisé de SocialHook.
Les images et les documents partagent le même pattern de téléchargement en deux étapes. La différence clé : les documents incluent un champ filename que vous devez conserver dans votre clé de stockage — c'est le nom que le client a donné au fichier et ce que vous voudrez afficher dans votre UI.
Les notes vocales enregistrées dans WhatsApp sont encodées au format OGG/Opus. Vous pouvez les identifier par le drapeau voice: true dans le payload audio et la valeur mime_type: "audio/ogg; codecs=opus". Ce format n'est pas supporté par OpenAI Whisper pour la transcription, et a un support de lecture limité dans les navigateurs.
La solution : convertir en MP3 avec ffmpeg. ffmpeg est l'outil universel de conversion audio, disponible sur tous les principaux OS et tous les environnements cloud.
Transcription des notes vocales avec OpenAI Whisper
Une fois que vous avez le MP3, envoyez-le à l'API Whisper d'OpenAI. Whisper supporte 57 langues, gère bien le bruit de fond, et coûte environ $0,006 par minute d'audio — une note vocale de 30 secondes coûte moins d'un centime à transcrire. La transcription devient ensuite du texte interrogeable et traitable par IA.
Que faire avec la transcription : Stockez-la aux côtés du fichier audio. Transmettez-la à votre agent IA comme message de l'utilisateur (au lieu de « message audio reçu »). Indexez-la dans votre base de données de recherche. Enregistrez-la dans votre CRM comme texte de conversation. Les clients envoient des notes vocales parce que la saisie est plus lente — traiter leurs notes vocales comme du texte consultable améliore considérablement la capacité de votre agent IA à comprendre et répondre correctement.
Modèles de stockage : organisez vos fichiers médias
La façon dont vous organisez les fichiers dans S3 ou GCS est importante pour les performances, la facturation et le débogage. Voici le pattern de clé de stockage qui s'adapte proprement à plusieurs clients et types de messages :
Une fonction qui reçoit un événement média normalisé et route vers le handler correct selon le type :
Node.js — universal media dispatcher
mediaDispatcher.js
async functiondispatchMedia(event) {
const { from, message } = event;
const { type } = message;
// Text messages — not media, handle separatelyif (type === 'text') returnhandleText(from, message.text.body);
// Non-media message typesif (['location', 'contacts', 'reaction', 'interactive'].includes(type)) {
returnhandleNonMedia(from, message);
}
// Media types — all require downloadswitch (type) {
case'image':
case'video':
case'sticker':
case'document': {
const result = awaithandleMediaMessage(message, from);
awaitsaveMediaRecord(from, result);
break;
}
case'audio': {
// Voice notes get transcribed; regular audio files just storedconst result = awaitprocessVoiceNote(message, from);
awaitsaveMediaRecord(from, result);
// If voice note was transcribed, treat transcript as text inputif (result.transcript?.text) {
console.log(`Voice note from ${from}: "${result.transcript.text}"`);
awaithandleText(from, result.transcript.text, { isVoiceNote: true });
}
break;
}
default:
console.warn(`Unhandled media type: ${type}`);
}
}
SocialHook : IDs médias pré-extraits en format normalisé
Lorsque vous utilisez SocialHook, le payload média arrive déjà extrait de l'enveloppe imbriquée de la Cloud API de Meta. Au lieu de naviguer dans entry[0].changes[0].value.messages[0], vous recevez un événement plat :
SocialHook normalized media event
// Image message
{
"platform": "whatsapp",
"event": "message.received",
"from": "+1 555 000 1234",
"message": {
"type": "image",
"id": "wamid.HBgL...",
"image": {
"id": "12345678901234", // ← use this to resolve URL"mime_type": "image/jpeg",
"caption": "Here's the damage to my package"
}
},
"signature_verified": true
}
// Voice note
{
"message": {
"type": "audio",
"audio": {
"id": "98765432109876",
"mime_type": "audio/ogg; codecs=opus",
"voice": true// ← this tells you to run OGG→MP3 conversion
}
}
}
Votre fonction dispatchMedia(event) ci-dessus reçoit ce format directement — aucune analyse supplémentaire nécessaire. L'ID média est à event.message.image.id (ou .audio.id, .document.id, etc.), prêt à alimenter resolveMediaUrl().
FAQ
Questions fréquentes
Comment télécharger des médias depuis un webhook WhatsApp Cloud API ?
Deux étapes : (1) Appelez GET graph.facebook.com/v21.0/{media_id} avec votre token d'accès pour obtenir une URL de téléchargement temporaire. (2) Récupérez cette URL (également avec votre token d'accès dans l'en-tête Authorization) pour obtenir les octets du fichier. Téléchargez immédiatement — l'URL expire en environ 5 minutes. Stockez les octets du fichier sur S3/GCS/disque, pas l'URL temporaire.
Pourquoi mon URL de téléchargement de médias WhatsApp retourne-t-elle 403 ?
Deux causes : (1) URL expirée — les URL de téléchargement de médias WhatsApp sont valides environ 5 minutes. Si vous avez stocké l'URL et l'avez récupérée plus tard, elle a expiré. Re-résolvez depuis l'ID média. (2) En-tête Authorization manquant — l'URL de téléchargement elle-même nécessite aussi Authorization: Bearer {ACCESS_TOKEN} dans la requête. Les URL de médias WhatsApp ne sont pas des URL CDN publiques.
Dans quel format sont les notes vocales WhatsApp et comment les convertir ?
Les notes vocales WhatsApp sont au format OGG/Opus (identifiées par voice: true dans le payload et mime_type: "audio/ogg; codecs=opus"). Convertissez en MP3 avec ffmpeg : ffmpeg -i input.ogg -codec:a libmp3lame -qscale:a 2 output.mp3. OGG/Opus n'est pas supporté par OpenAI Whisper ni par la plupart des navigateurs — convertissez toujours avant la transcription ou la lecture. Le code complet Node.js et Python est dans la section notes vocales ci-dessus.
Comment transcrire des notes vocales WhatsApp avec Whisper ?
Téléchargez le OGG → convertissez en MP3 avec ffmpeg → envoyez à l'API Audio Transcriptions d'OpenAI avec model: "whisper-1". Whisper retourne le texte de transcription. Le coût est ~$0,006 par minute d'audio. Une note vocale de 30 secondes coûte moins d'un tiers de centime. La transcription peut ensuite être traitée comme un message texte ordinaire par votre agent IA ou CRM.
Quelle est la durée de validité des IDs médias WhatsApp ?
Les IDs médias sont valides 30 jours. L'URL de téléchargement temporaire obtenue en résolvant l'ID est valide environ 5 minutes. Cela signifie que vous pouvez stocker en toute sécurité uniquement l'ID média dans votre base de données et le résoudre lorsque vous avez besoin du fichier (dans les 30 jours). Après 30 jours, le média est supprimé des serveurs de Meta et l'ID est invalide.
Quelles sont les limites de taille de fichier pour les médias WhatsApp ?
Par type : Image (JPEG, PNG) — 5 Mo. Audio — 16 Mo. Vidéo — 16 Mo. Document — 100 Mo. Sticker — 500 Ko statique, 100 Ko animé. Les messages avec des médias dépassant ces limites sont rejetés avant que votre webhook se déclenche — l'expéditeur voit un échec, pas vous.
Votre pipeline commence avec un événement webhook propre.
SocialHook livre chaque événement média WhatsApp — image, note vocale, document — en JSON pré-extrait à votre handler. Vous obtenez l'ID média prêt à résoudre, le type MIME et le drapeau voix. Pas d'analyse Cloud API. Branchez-le directement à votre fonction de téléchargement.
Arrêtez de gérer les API Meta. Commencez à construire.
Connectez votre premier compte Facebook, Instagram ou WhatsApp en moins de 2 minutes. Votre webhook reçoit son premier payload avant que votre café refroidisse.