Cómo manejar mensajes multimedia de WhatsApp en webhooks (imágenes, documentos, notas de voz)
22 de mayo de 2026
·
16 min de lectura
En esta guía: Tabla de referencia de tipos de medios · El vencimiento de 5 minutos de la URL · Pipeline de descarga completo · Todos los esquemas de payload de medios · Manejo de imágenes y documentos · Conversión de nota de voz OGG→MP3 · Transcripción con Whisper · Patrones de almacenamiento S3/GCS · Handler completo con todos los tipos · Formato normalizado de SocialHook
Tipos de medios: tabla de referencia completa
La Cloud API entrega 8 tipos de mensajes multimedia, cada uno con diferentes formatos, límites de tamaño y requisitos de manejo. Conoce las restricciones antes de construir el handler.
valor type
Formatos aceptados
Límite de tamaño
Notas especiales
🖼️
image
JPEG, PNG
5 MB
Opcional caption. GIF no admitido en línea — enviar como documento.
🎵
audio
AAC, AMR, MP3, OGG/Opus
16 MB
voice: true si se grabó en la app (OGG/Opus). Los archivos de audio regulares pueden variar. Siempre convierte OGG antes de la transcripción.
🎬
video
MP4, 3GPP
16 MB
Opcional caption. Se recomienda video H.264 + audio AAC para mayor compatibilidad.
📄
document
Cualquier tipo MIME que Meta acepte
100 MB
Incluye filename — guárdalo. PDF, DOCX, XLSX, imágenes como documentos, etc.
💿
sticker
WebP
Estático 500KB / Animado 100KB
animated: true si es animado. Formato WebP — los navegadores lo admiten de forma nativa ahora.
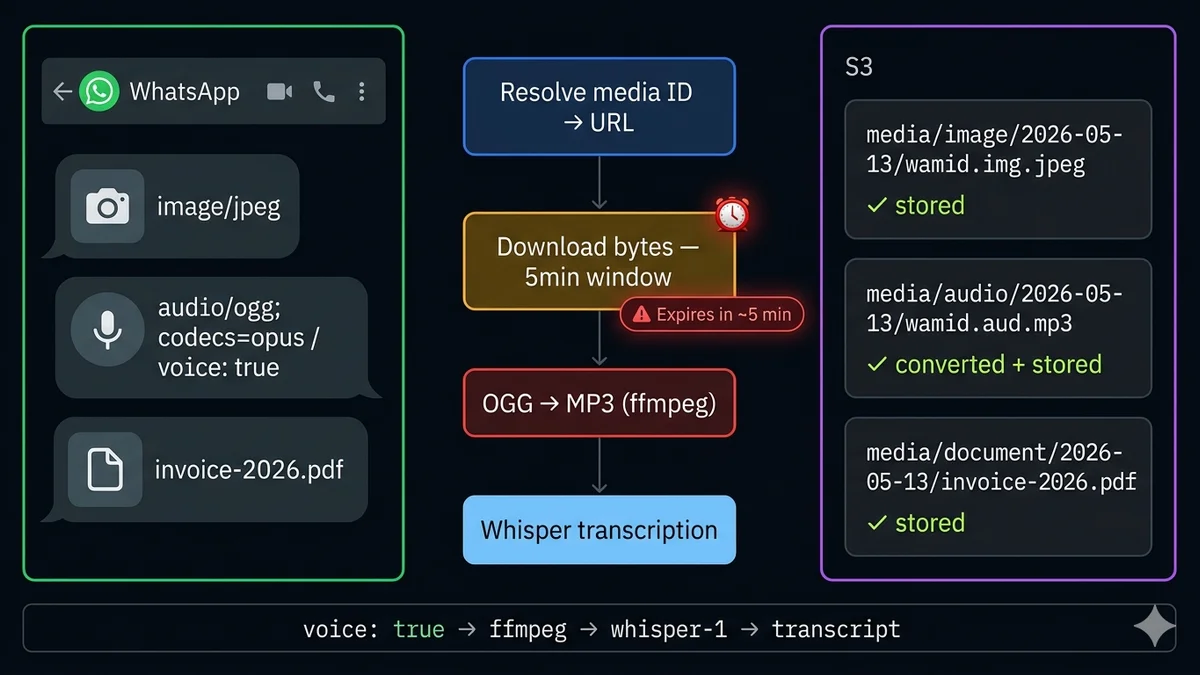
El vencimiento de 5 minutos — el detalle que arruina la mayoría de las implementaciones
Este es el detalle más comúnmente omitido en el manejo de medios de WhatsApp, y causa la mayoría de los errores en producción. Cuando llamas al endpoint de medios de la Cloud API para resolver un ID de medio, recibes una URL de descarga temporal. Esa URL es válida por aproximadamente 5 minutos.
Los dos patrones que usan los desarrolladores — y por qué uno falla:
❌ Almacenar la URL, descargar después — recibes el webhook, llamas al endpoint de medios, almacenas la URL temporal en tu base de datos para procesamiento asíncrono. Para cuando tu worker la recoge, la URL ha expirado. Obtienes un 403. Este patrón falla.
✓ Descargar inmediatamente, almacenar el archivo — recibes el webhook, inmediatamente resuelves el ID de medio a una URL, inmediatamente descargas los bytes, almacenas el archivo en tu propio almacenamiento (S3, GCS, disco), guarda solo la ruta de almacenamiento en tu base de datos. El procesamiento asíncrono trabaja con el archivo almacenado. Este patrón es correcto.
Alternativa: almacenar el ID de medio, resolver bajo demanda. Si no necesitas el archivo de inmediato, puedes almacenar solo el ID de medio y resolverlo cuando necesites el archivo. Los IDs de medio son válidos por 30 días — mucho más que la URL de descarga temporal. Esto es útil cuando no estás seguro de si alguna vez necesitarás el binario (p. ej. stickers que podrías ignorar). Solo ten en cuenta que la llamada de resolución agrega latencia cuando finalmente lo necesites.
El pipeline de descarga: ID → URL → bytes → almacenamiento
1
Recibir webhook — extraer ID de medio
msg.image.id / msg.audio.id / msg.document.id — NO es una URL, solo una referencia
2
Devolver HTTP 200 inmediatamente haz esto primero
Confirma a Meta antes de cualquier descarga. Envía el procesamiento de medios a la cola asíncrona.
3
Resolver ID de medio → URL de descarga temporal
GET graph.facebook.com/v21.0/{media_id} — requiere Authorization: Bearer {token} — devuelve url (vence en ~5min) + mime_type + file_size
4
Descargar los bytes del archivo dentro de 5 minutos
GET {download_url} — TAMBIÉN requiere Authorization: Bearer {token} — devuelve bytes binarios sin procesar
Esta es la estructura exacta del objeto value del webhook para cada tipo de medio. El anidamiento desde el envoltorio de nivel superior (entry[0].changes[0].value.messages[0]) ya está extraído cuando se usa el formato normalizado de SocialHook.
Las imágenes y los documentos comparten el mismo patrón de descarga en dos pasos. La diferencia clave: los documentos incluyen un campo filename que deberías preservar en tu clave de almacenamiento — es el nombre que el cliente dio al archivo y lo que querrás mostrar en tu UI.
Las notas de voz grabadas en WhatsApp están codificadas en formato OGG/Opus. Puedes identificarlas por el indicador voice: true en el payload de audio y el valor mime_type: "audio/ogg; codecs=opus". Este formato no es compatible con OpenAI Whisper para transcripción, y tiene soporte limitado de reproducción en navegadores.
La solución: convierte a MP3 usando ffmpeg. ffmpeg es la herramienta universal de conversión de audio, disponible en todos los principales sistemas operativos y entornos en la nube.
Una vez que tienes el MP3, envíalo a la API Whisper de OpenAI. Whisper admite 57 idiomas, maneja bien el ruido de fondo y cuesta aproximadamente $0.006 por minuto de audio — una nota de voz de 30 segundos cuesta menos de un centavo para transcribir. La transcripción luego se convierte en texto consultable y procesable por IA.
Qué hacer con la transcripción: Almacénala junto al archivo de audio. Pásala a tu agente de IA como el mensaje del usuario (en lugar de "mensaje de audio recibido"). Indexla en tu base de datos de búsqueda. Regístrala en tu CRM como el texto de la conversación. Los clientes envían notas de voz porque escribir es más lento — tratar sus notas de voz como texto buscable mejora drásticamente la capacidad de tu agente de IA para entender y responder correctamente.
Patrones de almacenamiento: organiza tus archivos de medios
Cómo organizas los archivos en S3 o GCS importa para el rendimiento, la facturación y la depuración. Aquí está el patrón de clave de almacenamiento que escala limpiamente a través de múltiples clientes y tipos de mensajes:
Handler completo de webhook de medios (todos los tipos)
Una función que recibe un evento de medios normalizado y dirige al handler correcto según el tipo:
Node.js — universal media dispatcher
mediaDispatcher.js
async functiondispatchMedia(event) {
const { from, message } = event;
const { type } = message;
// Text messages — not media, handle separatelyif (type === 'text') returnhandleText(from, message.text.body);
// Non-media message typesif (['location', 'contacts', 'reaction', 'interactive'].includes(type)) {
returnhandleNonMedia(from, message);
}
// Media types — all require downloadswitch (type) {
case'image':
case'video':
case'sticker':
case'document': {
const result = awaithandleMediaMessage(message, from);
awaitsaveMediaRecord(from, result);
break;
}
case'audio': {
// Voice notes get transcribed; regular audio files just storedconst result = awaitprocessVoiceNote(message, from);
awaitsaveMediaRecord(from, result);
// If voice note was transcribed, treat transcript as text inputif (result.transcript?.text) {
console.log(`Voice note from ${from}: "${result.transcript.text}"`);
awaithandleText(from, result.transcript.text, { isVoiceNote: true });
}
break;
}
default:
console.warn(`Unhandled media type: ${type}`);
}
}
SocialHook: IDs de medios pre-extraídos en formato normalizado
Cuando usas SocialHook, el payload de medios llega ya extraído del envoltorio anidado de la Cloud API de Meta. En lugar de navegar por entry[0].changes[0].value.messages[0], recibes un evento plano:
SocialHook normalized media event
// Image message
{
"platform": "whatsapp",
"event": "message.received",
"from": "+1 555 000 1234",
"message": {
"type": "image",
"id": "wamid.HBgL...",
"image": {
"id": "12345678901234", // ← use this to resolve URL"mime_type": "image/jpeg",
"caption": "Here's the damage to my package"
}
},
"signature_verified": true
}
// Voice note
{
"message": {
"type": "audio",
"audio": {
"id": "98765432109876",
"mime_type": "audio/ogg; codecs=opus",
"voice": true// ← this tells you to run OGG→MP3 conversion
}
}
}
Tu función dispatchMedia(event) anterior recibe este formato directamente — sin necesidad de análisis adicional. El ID de medio está en event.message.image.id (o .audio.id, .document.id, etc.), listo para alimentar a resolveMediaUrl().
FAQ
Preguntas frecuentes
¿Cómo descargo medios de un webhook de WhatsApp Cloud API?
Dos pasos: (1) Llama a GET graph.facebook.com/v21.0/{media_id} con tu token de acceso para obtener una URL de descarga temporal. (2) Haz fetch de esa URL (también con tu token de acceso en el encabezado Authorization) para obtener los bytes del archivo. Descarga inmediatamente — la URL vence en aproximadamente 5 minutos. Almacena los bytes del archivo en S3/GCS/disco, no la URL temporal.
¿Por qué mi URL de descarga de medios de WhatsApp devuelve 403?
Dos causas: (1) URL vencida — las URLs de descarga de medios de WhatsApp son válidas por aproximadamente 5 minutos. Si almacenaste la URL y la obtuviste después, venció. Re-resuelve desde el ID de medio. (2) Encabezado Authorization faltante — la URL de descarga en sí también requiere Authorization: Bearer {ACCESS_TOKEN} en la solicitud. Las URLs de medios de WhatsApp no son URLs de CDN públicas.
¿En qué formato están las notas de voz de WhatsApp y cómo las convierto?
Las notas de voz de WhatsApp están en formato OGG/Opus (identificadas por voice: true en el payload y mime_type: "audio/ogg; codecs=opus"). Convierte a MP3 con ffmpeg: ffmpeg -i input.ogg -codec:a libmp3lame -qscale:a 2 output.mp3. OGG/Opus no es compatible con OpenAI Whisper ni con la mayoría de los navegadores — siempre convierte antes de la transcripción o reproducción. El código completo en Node.js y Python está en la sección de notas de voz arriba.
¿Cómo transcribo notas de voz de WhatsApp con Whisper?
Descarga el OGG → convierte a MP3 con ffmpeg → envía a la API de Transcripciones de Audio de OpenAI con model: "whisper-1". Whisper devuelve el texto de la transcripción. El costo es ~$0.006 por minuto de audio. Una nota de voz de 30 segundos cuesta menos de un tercio de un centavo. La transcripción puede luego ser tratada como un mensaje de texto regular por tu agente de IA o CRM.
¿Cuánto tiempo son válidos los IDs de medios de WhatsApp?
Los IDs de medios son válidos por 30 días. La URL de descarga temporal que obtienes al resolver el ID es válida por aproximadamente 5 minutos. Esto significa que puedes almacenar de forma segura solo el ID de medio en tu base de datos y resolverlo cuando necesites el archivo (dentro de los 30 días). Después de 30 días, los medios se eliminan de los servidores de Meta y el ID es inválido.
¿Cuáles son los límites de tamaño de archivo para los medios de WhatsApp?
Por tipo: Imagen (JPEG, PNG) — 5 MB. Audio — 16 MB. Video — 16 MB. Documento — 100 MB. Sticker — 500 KB estático, 100 KB animado. Los mensajes con medios que superen estos límites son rechazados antes de que tu webhook se active — el remitente ve un fallo, no tú.
Tu pipeline comienza con un evento de webhook limpio.
SocialHook entrega cada evento de medios de WhatsApp — imagen, nota de voz, documento — como JSON pre-extraído a tu handler. Obtienes el ID de medio listo para resolver, el tipo MIME y el indicador de voz. Sin análisis de la Cloud API. Solo conéctalo directamente a tu función de descarga.